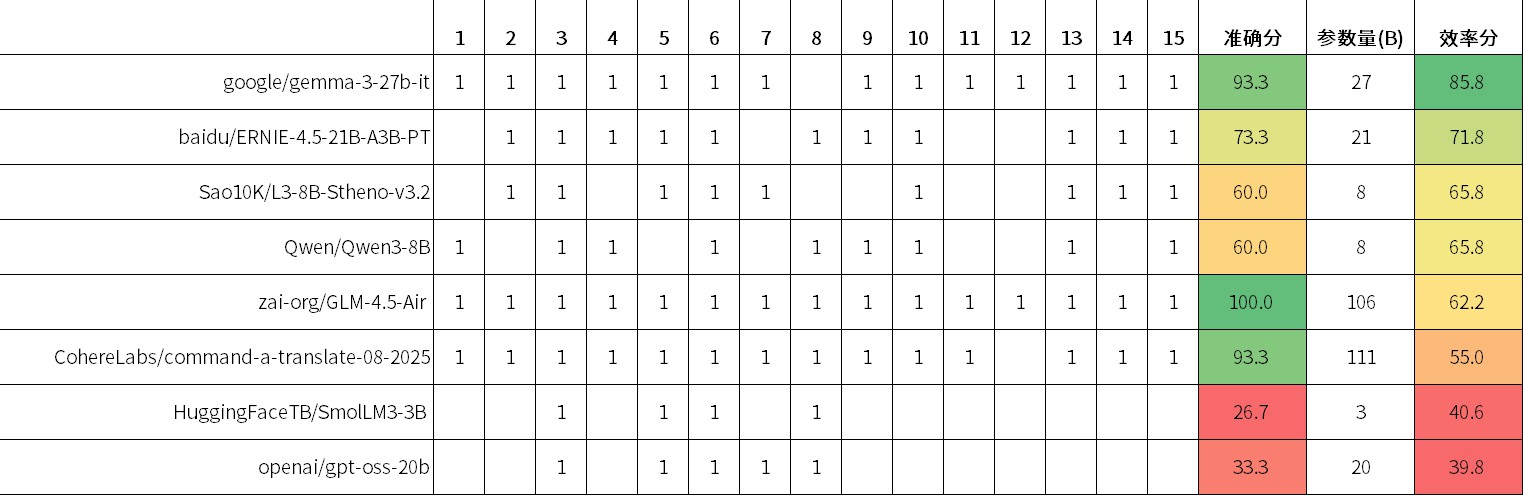
随性比较了多个开放权重的大型语言模型特别在华文网路流行语言上的表现,并分别使用准确分和效率分两个指标进行排序。
测试 Prompt
统一指令:请将以下中文句子翻译成英文。
- 你是GG还是MM?
- 我去吃饭了,886!
- 你真是个超级大菜鸟。
- 表酱紫嘛,人家也不是故意的。
- 晕,楼主的话真是火星文,看不懂。
- 他是个人才,我顶!
- 灌水是一种美德,请勿拍砖。
- 你out了,现在不兴这个了。
- 偶粉稀饭你的建议哦!
- 请斑竹把这个ID封掉。
- LZ是新手,请多关照,第一次发帖,有点紧张。
- 楼下的不要抢,板凳是我的!
- 偶是来打酱油的,你们继续,继续。
- 偶要去碎觉了,88。
- 这个帖子的内容太雷了,我的三观都被刷新了。
评分方法
每个模型有两个基础指标:准确分 Q和参数量 R(单位 Billion)。
采用人工评价是否整句正确,整句正确则积一分,然后按照正确率的值乘以 100 记为准确分。效率分的计算方法如下:
- 对 Q 归一化:
Q̂ = (Q − Qmin) / (Qmax − Qmin) - 对 R 反向归一化:
R̂ = (Rmax − R) / (Rmax − Rmin) - 加权合成:
Eraw = wQ · Q̂ + wR · R̂,且wQ + wR = 1 - 映射到 1–100:
E = 1 + 99 × Eraw,并裁剪在 [1, 100]
结果
下图为按准确分排序的结果:
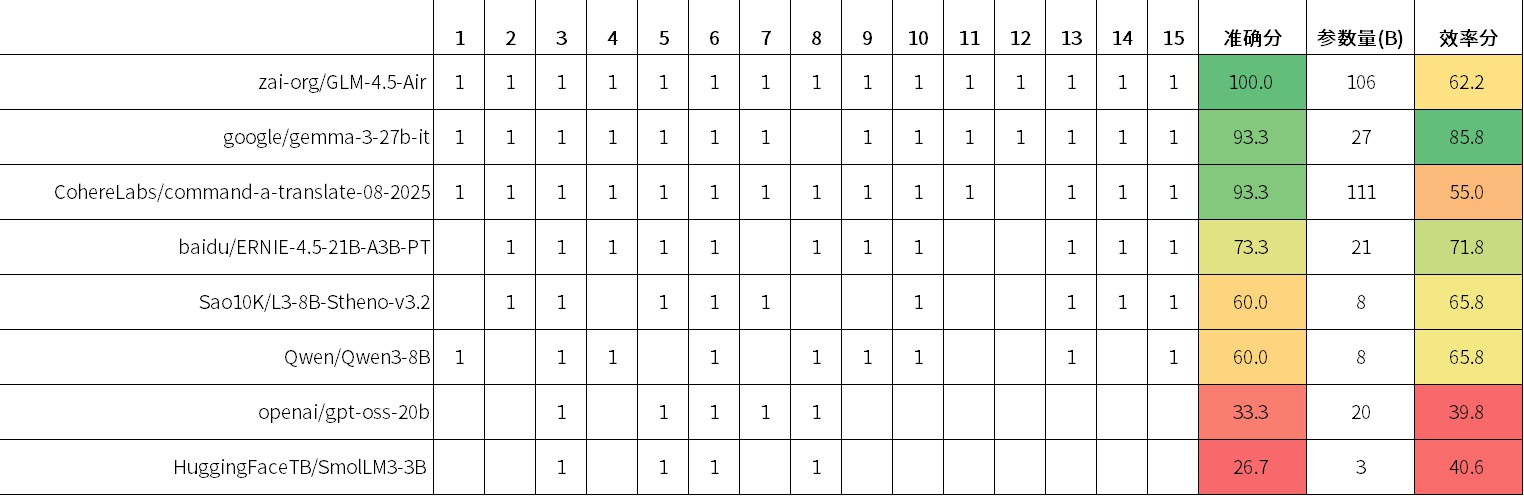
下图为按效率分排序的结果: