所用数据均采集自互联网公开来源,并在采集与处理阶段经过严格的匿名化脱敏,不含任何可识别的个人身份信息。所有分析内容及图表仅供科学研究与技术交流使用。数据来源:赛博忏悔室 @cyber_confessional,该频道所有内容在发布时、以及本次的处理中均已经进行多次匿名化处理。
使用 Python 调用的核心库包括用于数据处理的pandas、用于中文分词的jieba、用于可视化的matplotlib、用于生成词云的wordcloud、用于聚类与降维的scikit-learn以及用于词向量生成的sentence-transformers。
Step 1
进行数据清洗,同时剔除 2026年1月1日 之后的数据。分词处理后去除停用词,应用自定义的停用词表过滤掉常见的虚词和无意义的语气词,只保留长度大于 1 的有效词汇。
Step 2
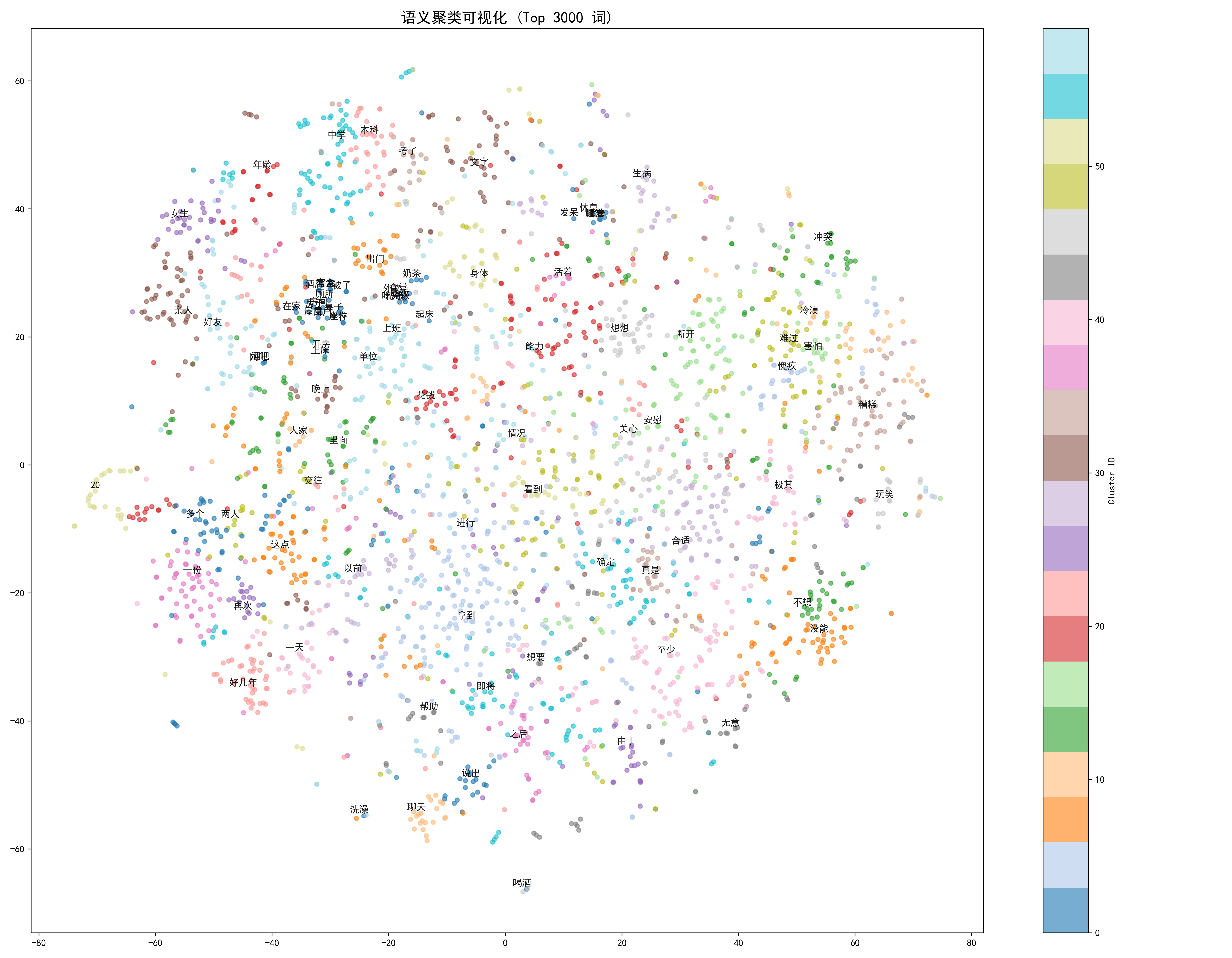
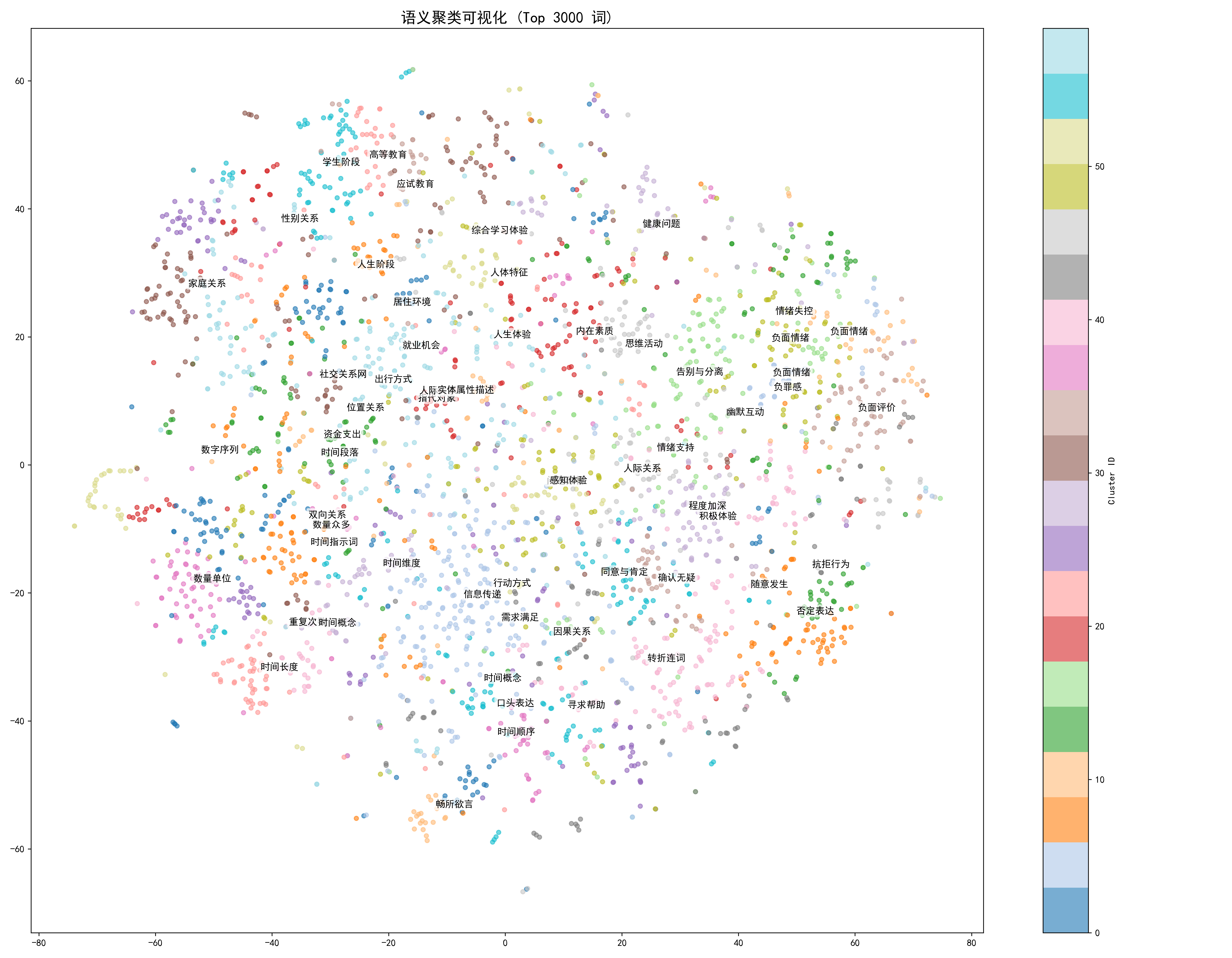
计算绝对频次,随后进行数据标准化处理,导出生成了标准化热度表以及绝对频次表。使用 BAAI/bge-large-zh-v1.5 模型将排名前 3000 的高频词转换为高维向量,随后采用 K-Means 算法将关键词聚类为 60 个语义簇,并选取距离中心最近的词作为该话题的代表命名或者使用 Google/Gemma3-12B 模型寻找代表词。利用t-SNE算法生成语义地图,将高维词向量降维至二维平面并绘制散点图。
中心词:
LLM 寻找代表词:
Step 3
基于标准化后的年均热度,生成了年度词云。
2023:

2024:

2025:

Step 4
制作了趋势分析图,包括展示持续热度最高的话题的总量Top 10图表,以及基于标准差筛选的波动Top 10图表,用于展示爆发性最强或波动最大的话题。
Step 5
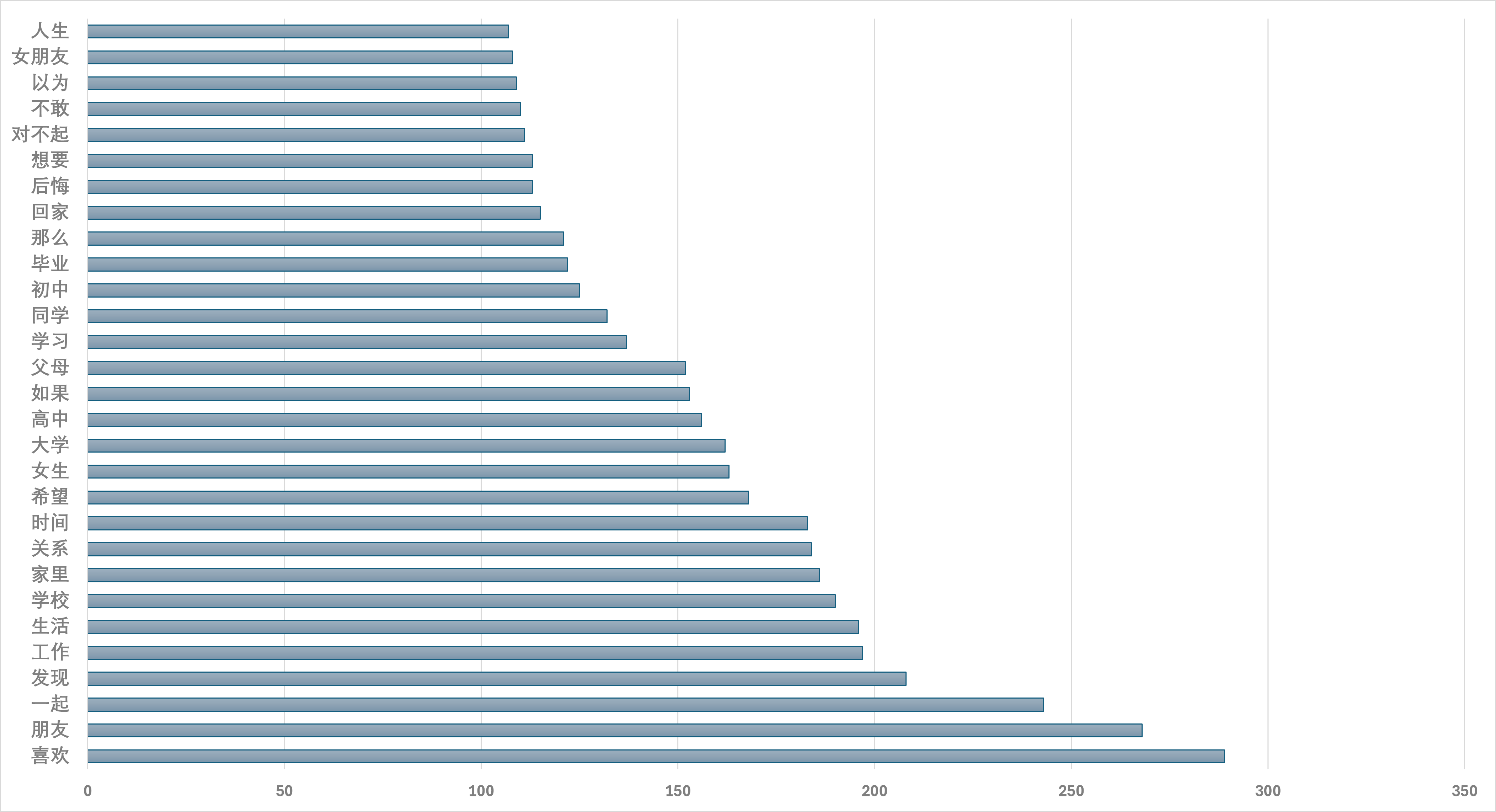
剔除所有时间、程度、数量、地点等非主题词语,使用人工方式处理绝对数量上的热门主题词,并以 MS Office Excel 制图。